Overview

MMNeedle Evaluation Overview. Correct answers are marked with checkmark (✓), while the incorrect answers are marked with cross (✗).
Our evaluation setup involves the following key components:
- (a) Needle Sub-Image: The needle sub-image to be retrieved based on the given caption.
- (b) Haystack Image Inputs: The long-context visual inputs consist of M images, each stitched from N × N sub-images.
- (c) Text Inputs (Instructions and Caption): Detailed instructions to MLLMs, followed by a caption describing the needle, i.e., sub-image 20.
- (d) LLM Outputs: The answers from different MLLMs, indicating their ability to accurately locate the needle in the haystack based on the given caption. The expected output is composed of the model's identification of the index, row, and column of the matching sub-image. The results showcase the comparative performance of various models: GPT-4o correctly predicts the exact location of the needle; Gemini Pro 1.5 only correctly predicts the image index of the needle; other API models predict incorrect locations; open-source models often output with wrong formats.
Example Results
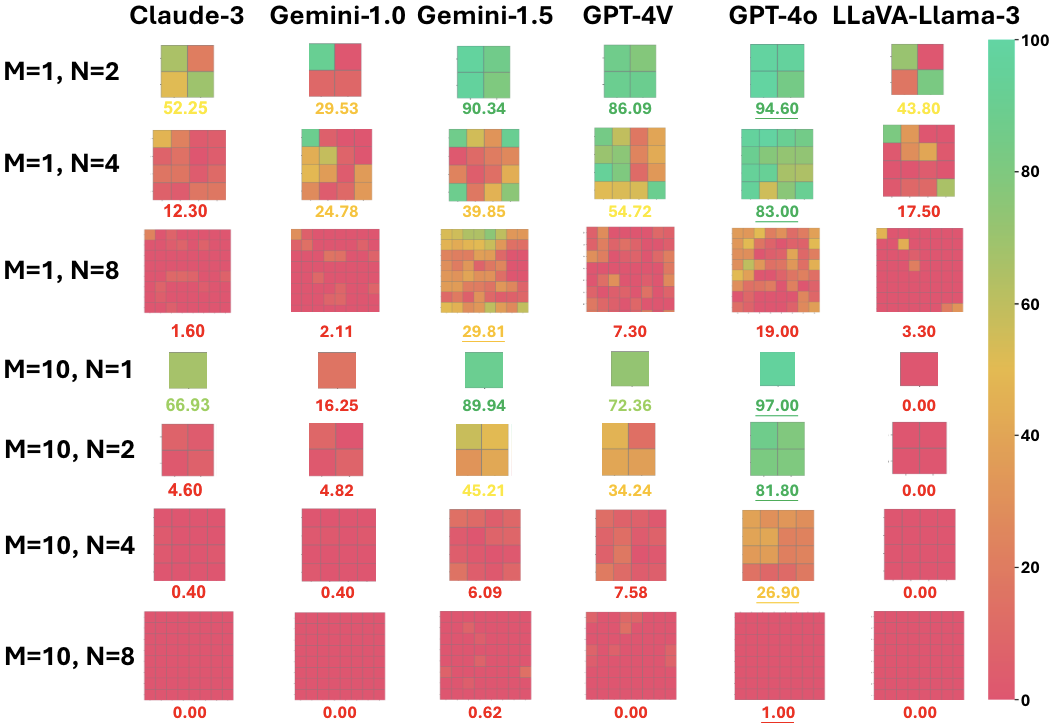
MMNeedle Evaluation Performance Comparison. Claude-3 refers to Claude 3 Opus, and Gemini-1.0/1.5 refers to Gemini Pro 1.0/1.5. The x-axis shows the results of different models, and the y-axis shows the results on various input image numbers M and stitching size N. For each row, i.e., setting (M,N), we show the average accuracy (%) of each model. For each stitched image, the color of row r, column c indicates the accuracy of predicting the exact position for samples with the "needle" sub-image in position (r,c) of the stitched image. For the M=10 setting, we show the average accuracy of each location (r,c) over 10 images. A redder cell indicates lower accuracy, while a greener cell indicates higher accuracy. The best result for each row is marked with underlining.
Our findings underscore a considerable performance gap between models and reveal the hallucination problem in state-of-the-art MLLMs through negative samples. For example, we find that:
- There is still a large performance gap between state-of-the-art API-based and state-of-the-art open-source models.
- Accuracy drops significantly with more images in the haystacks, even for state-of-the-art API-based MLLMs such as Claude 3 Opus and Gemini 1.0 Pro.
- All models (including Claude 3 Opus, Gemini 1.5 Pro, and GPT-4V) perform poorly in MMNeedle settings with sub-images (e.g., N × N = 2 × 2 = 4 sub-images in Fig. 1); this is true even for the best model, GPT-4o, whose accuracy drops from 97.00% for M = 10 images without sub-images (i.e., equivalent to 10 images in the haystack) to 26.90% for M = 10 images with N × N = 4 × 4 = 16 sub-images for each image (equivalent to 160 images in the haystack). See more results in Sec. 4.
Highlights
The highlights of our MMNeedle benchmark include:
- Comprehensive Dataset. Our dataset ensures sufficient samples for each setting, with a total number of 40,000 images, 560,000 captions, and 280,000 needle-haystack pairs.
- Diverse Settings. Our benchmark covers diverse settings with varying context lengths, single and multiple needles, as well as positive and negative samples, among others (details in Sec. 3).
- Coarse-to-Fine Evaluation Metrics. We establish a set of evaluation metrics, including “existence accuracy”, “index accuracy”, and “exact accuracy”, to holistically evaluate MLLM at the sequence-, image-, and sub-image- levels (details in Sec. 3.5).
- Wide Coverage. Our evaluation covers both state-of-the-art API-based and state-of-the-art open-source MLLMs, shedding light on their long-context capabilities.
BibTeX
@inproceedings{wang-etal-2025-multimodal,
title = "Multimodal Needle in a Haystack: Benchmarking Long-Context Capability of Multimodal Large Language Models",
author = "Wang, Hengyi and
Shi, Haizhou and
Tan, Shiwei and
Qin, Weiyi and
Wang, Wenyuan and
Zhang, Tunyu and
Nambi, Akshay and
Ganu, Tanuja and
Wang, Hao",
editor = "Chiruzzo, Luis and
Ritter, Alan and
Wang, Lu",
booktitle = "Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)",
month = apr,
year = "2025",
address = "Albuquerque, New Mexico",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.naacl-long.166/",
pages = "3221--3241",
ISBN = "979-8-89176-189-6"}